Frequently Asked Questions about our website and our DuplicateAddress Services
Last Modified: 12 Jan 2022
Validity: The frequently asked questions (FAQ) may improve and change from time to time. To stay updated, visit this page periodically to know the current status. Existing clients will be informed of any change.
Feedback: If you have any comments or questions on this FAQ or on any other matter, let us know by using our Contact Us page.
1. What services are provided?
We detect and optionally remove duplicates in identity data usually based on “postal addresses” and “name & postal addresses”. Organization, department, designation, phone, email, gender, any identification tag are some information that could be used. Any kind of information can be used.
2. What output would you receive?
One of:
- Clusters of duplicate records with a number between 1 to 100 indicating the best match score within the cluster – you handle subsequent removal of duplicates – see the sample result layout below
- Automatic removal of duplicates – two lists are provided – a list of duplicate records with an indication of those records suggested for removal and consolidation, and a list of records without duplicates
- Removal of duplicates after examining each cluster (eyeballing) – a list of duplicate records with an indication of those records suggested for removal and consolidation, and a list of records without duplicates – RECOMMENDED SOLUTION
3. What duplicate-detection-methods possible?
The most common are name and address, and, address. Other duplicate detection methods such as organisation and household are possible – let us know your requirement and we will advise you accordingly.
5. What are the differences between one-time and on-going jobs?
A one-time job is when data is sent to us once in one or more files and the results are sent to you once. Three months after technical and commercial completion all files are erased from our servers.
An on-going job is when data is sent to us from time to time and only changes are sent back. Optionally, the latest complete output is sent back every time.
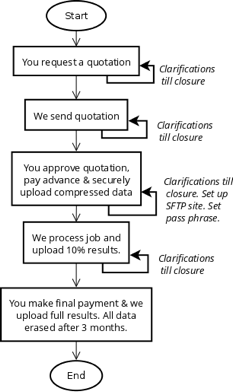
6. Process flow chart for a one-time job:
7. Process flow chart for an on-going job:
Similar to a one-time job. Will be clarified during quotation stage.
8. How to ask for a quotation?
Go to the Request quotation page and provide your name, address, country, email, contact phone, purpose, sample data of around 50 to 500 addresses, and, duplicate-detection-method (name and address, or, address – see FAQ on What duplicate-detection-methods possible). Provide the count of records in the full file. We will send you a quotation.
NOTE: The sample data will not be securely transmitted on the internet but will be handled securely by us once received.
9. What if you have multiple input data file types and/or multiple layouts?
Compress all the sample data files together and upload as a single file. Provide description and count of records for each data file. The compressed file should be within 100 KB in size (please contact us if the size is much more). Suggest a suitable file layout & type in which the combined result data can be presented; else, we can proceed once you concur with our suggested output file layout & type.
All results are compressed and encrypted using a pass phrase before it is transmitted to protect the data. The secure method to exchange pass phrases will be individually discussed beforehand. We request the compression and encryption of all input data (except sample data) before sending it to us. Sample data is usually not encrypted.
9.2. What is a pass phrase & how is it communicated between us?
A pass phrase is a long password that ensures more secure encryption of data. We will discuss with you after we receive your first quotation request.
9.3. How do you send us operational data and receive results?
For very large data, after receiving the first advance from you, you can set up your own Secure File Transfer Protocol (SFTP) site that we can access, else, we will set up a SFTP location for you with sign-in name and password. You can upload your compressed and encrypted data and download your compressed and encrypted results from the SFTP site. Small batches of data of up to one million records can be sent both ways by email after compressing & encrypting.
We ensure that the data will remain secure in our premises. After each job is closed, a process that overwrites all information securely erases input, result and work files. Access to the server downloading, processing and uploading your data is strictly controlled. If we set up the SFTP site then the security provided by reputed cloud services vendors shall apply and data on the SFTP site cannot be scrubbed. Also, all data at the SFTP site will be pass phrase encrypted.
We expect you to remove data from the SFTP location at your convenience. If we set up the SFTP site, files are securely erased 3 months after technical and commercial completion.
9.5. You want to send the sample data securely:
Let us know using the Contact us form. We will advise you accordingly.
9.6. Personal Privacy Policy: See here.
We start after receiving a 50% advance. On completion we will advise you of run statistics and provide you with 10% of the duplicate detection result. Complete results will be provided after commercial completion.
You transfer the payment directly into our bank account. Details will be given in our quotation.
12. Which countries are supported?
All.
13. Is country information mandatory?
Yes. Country should be explicitly or implicitly specified. Each address must have country information, preferably as a separate field; else, all records must be pre-defined to belong to the same known country.
14. Are different countries handled together or separately?
The countries listed below are separated before processing and the results are delivered separately:
All Arabic speaking countries (separately), Argentina, Australia, Belgium, Borneo, Brazil, Cambodia, Canada, Chile, China, Colombia, Czech, Denmark, Estonia, Finland, France, Germany, Greece, Hong Kong, Hungary, India, Indonesia, Ireland, Israel, Italy, Japan, Korea, Laos, Luxembourg, Malaysia, Mexico, Myanmar, Netherlands, New Zealand, Norway, Peru, Philippines, Portugal, Puerto Rico, Singapore, Slovakia, South Africa, Spain, Sweden, Switzerland, Taiwan, Thailand, Turkey, UK, USA and Vietnam.
Countries not listed above are usually processed together and their result is delivered together.
15. What characters are permitted in input postal address data?
All permitted characters from the Latin-1 (ISO/IEC 8859-1) set given below:
Permitted characters:
” # & ‘ ( ) , – . / 0 1 2 3 4 5 6 7 8 9 : ; A B C D E F G H I J K L M N O P Q R S T U V W X Y Z a b c d e f g h i j k l m n o p q r s t u v w x y z À Á Â Ã Ä Å Æ Ç È É Ê Ë Ì Í Î Ï Ð Ñ Ò Ó Ô Õ Ö Ø Ù Ú Û Ü Ý à á â ã ä å æ ç è é ê ë ì í î ï ð ñ ò ó ô õ ö ø ù ú û ü ý ÿ
The most common character of space is permitted.
Characters that are permitted but we suggest that their use be reviewed by you:
! $ % * + < = > ? @ [ \ ] ^ _ ` { | } ~ ¡ ¢ £ ¤ ¥ ¦ § ¨ © ª « ¬ ® ¯ ° ± ² ³ ´ µ ¶ · ¸ ¹ º » ¼ ½ ¾ ¿ × Þ ß ÷ þ
Examine the list of permitted characters to see if all information can be processed. For some languages like Dutch, Finnish, French, German, Hungarian and Turkish some characters may not be in the list above. Almost always this will not be a problem as an equivalent form should be possible. We will check each file and advise you. In rare cases a work around may be needed; such as replace a character by another set of permitted characters.
Characters that are not permitted in the data: All control characters (non printable characters).
Control characters that are not permitted in data but permitted in the file: Record separator characters such as carriage-return <CR>, line-feed <LF> or new-line “\n”. The tab character “\t” is used if the fields are tab separated values (TSV).
16. What if other characters are detected in the input name and postal address data that cannot be processed?
We will advise you. You could opt to resend the data to us after removing; else, under your instructions, we will sanitize the data by replacing these other characters by the space character or by another set of permitted characters on your behalf. This is part of the pre-de-duplication sanitizing process.
17. Why are some characters permitted but we suggest that they should not be used?
These characters usually are not part of a postal address and reduce quality of processing. We will advise you if these characters are detected and depending on your instructions will either wait for you to resend the data after removing, or, process the data as it is, or, replace the other characters by the space character on your behalf.
18. What if any field contains multiple, leading or trailing spaces?
Multiple spaces are replaced by a single space. Leading and/or trailing space are removed. We will advise you. You could opt to resend the data to us after removing extra spaces; else we will replace the extra space characters on your behalf. This is also part of the pre-de-duplication sanitizing process.
19. If we sanitize the data before de-duplication, how are the results presented ?
Usually we will present the results using the sanitized data. You could opt for the result to be presented in the original form, or, with both. Presenting in pre-sanitized form or both pre & post sanitized form will incur an extra effort for us which we will advise before hand and will wait for your approval before proceeding.
20. Data encryption & compression (compressing with pass phrase)
All results would be presented after compression & encryption with a pre-arranged pass phrase protected compressed (zipped) file.
We request that all input be compressed & encrypted with the same pre-arranged pass phrase before uploading or sending to us.
21. What file types of input data preferred?
Tab separated variable (TSV), comma separated variable (CSV), or, a spreadsheet (if less than one million records) may be provided.
22. What file types of input data possible?
Any other file type of your choice including XML, JSON or YAML is possible. There may be an extra effort on our part applicable for any other file type, which we will advise before hand after examining your sample data and will wait for your approval before proceeding.
23. What special precautions for CSV (comma separated variable) data?
All fields must be quoted with double apostrophes at both ends with a comma separating fields, e.g. “John Smith”,”35 Minto Road”. Each double apostrophe within the data must be repeated, e.g. “Apollo”, 25 Cambridge Gardens in Hastings in Sussex becomes “””Apollo””, 25 Cambridge Gardens”,”Hastings”,”Sussex”
24. What layout & file type of result data preferred?
Our preferred result file type is Tab separated variable (TSV). The layout will, as far as possible, be similar to the input you send. We would specify the layout in our quotation. We will be happy to work out an output layout more convenient for you.
25. What other file types of result data possible?
CSV (comma separated variable), or, a spreadsheet may be provided on your request. Other file types of XML, JSON or YAML are possible. There may be an extra effort involved for other file types, which we will advise before hand and will wait for your approval before proceeding.
A sample result layout is given below:
|
Cluster number |
Best matching score within cluster |
Record identification |
Person or organization name | Address | City and country |
|---|---|---|---|---|---|
|
1 |
78 |
3 |
Jean-Jacques Martineau | 14, rue de Strasbourg, 1100, Chalon sur Saone | France |
|
1 |
78 |
18 |
Martineua | Strasbourg, 1100 | Chalon sur Saône, France |
|
2 |
92 |
14 |
Crocodile | 10, rue de l’Outre, 67000 | France |
|
2 |
92 |
21 |
Le Crocodile | 10, rue de l’Outre, 67000 | Strasbourg, France |
|
2 |
89 |
42 |
Crocodil | 10, rue de l’Outre Strasbourg | France |
Note the variations in spelling, structure and content. This is a simplification of one of the actual output layouts possible, e.g. the clusters are subdivided into groups where each record in the group has a match with all other records in a group (as opposed to the cluster where each record is matched with at least one other record, and may or may not be matched with all other records in the cluster). We will explain when sending the first results.
Obtained if the same structure is used across files & information is separated into individual fields. The next best if there is some segregation with minimum grouping, i.e. person name in one or more fields, designation, organisation, address part 1 (building, street, sub area, area), address part 2 (city, district, state, country), post code.
We can process inputs similar to a postal label layout or if the complete address appears in one string.
28. Information used for duplicate detection:
- Identity or internal record number, e.g. national ID – MANDATORY
- Person name – MANDATORY if search for individuals
- Designation
- Organisation
- Address part 1 (building & street details, sub area, area) – MANDATORY
- Address part 2 (city, district/county/canton, state) – MANDATORY
- Post code – Recommended
- Country – MANDATORY – implicitly or explicitly
- Phone(s)
- Date, e.g. birth, incorporation, marriage – date format should be uniform (ddmmyyyy or mm-dd-yy, etc. yyyy-mm-dd preferred)
- Any two attribute fields each of up to 255 bytes length
29. Multiple records for the same person:
A person can have multiple addresses, e.g. a person can have a residence and work address, or more. Or the person may have multiple phones. All these can be processed.
In case an initial very quick sample result is needed, then a preliminary result set is quickly provided. Subsequently, complete output with further duplicates found is delivered. Some clusters may merge.